

Prometheus
오픈소스 Monitoring / Alert 솔루션이다.

Prometheus Architecture
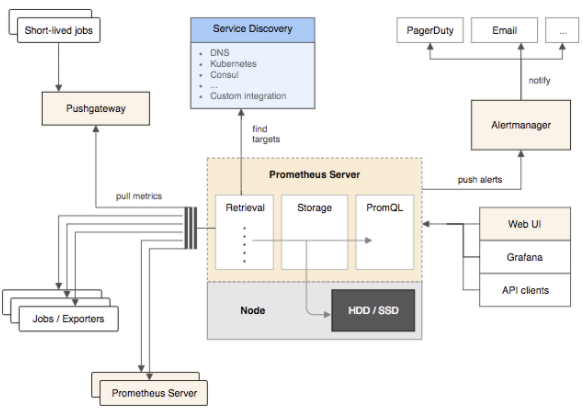
프로메테우스는 데이터를 수치화하는 job, 직접 또는 push gateway를 이용하는 short-lived job에서 값을 전달받은 메트릭으로부터 데이터를 수집한다.
모든 수집된 데이터는 로컬에 저장되며 이 데이터를 기반으로 룰을 실행하여 새로운 시계열 데이터를 기록하거나 집계하고 이벤트(alert)를 생성한다.
Grafana 또는 다른 API Consumer들은 이렇게 수집된 데이터를 시각화하는 데 사용된다.

대부분 모니터링 시스템은 메트릭을 수집할 때 메트릭이 발생한 서버에서 중앙 서버로 데이터를 전송해주는 구조(push)로 되어 있다.
하지만, 프로메테우스는 중앙 서버(prometheus server)에서 메트릭을 polling 해서 가져가는 구조(pull)로 되어 있다.
장점
모든 데이터를 HTTP(REST) Pull 기반으로 가져온다. (Push도 가능은 하다.) pull 방식의 구조이기 때문에 모든 메트릭에 대한 데이터를 중앙 서버로 보내지 않아도 된다. (push 방식의 기존 시스템은 부하가 높은 상황에서 fial point가 생성된다.)
모든 데이터를 수집하지 않고 일정 주기(Default : 15s)로 발생하는 메트릭을 수집하여 추이나 모니터링을 할 수 있다.
시계열(일정 시간 간격으로 배치된 데이터들의 수열)을 기반으로 하는 다차원 데이터 모델, 다차원 데이터 모델을 활용할 수 있는 유연한 PromQL을 제공한다.
분산 스토리지에 대해서 어떠한 의존성도 없다.
모니터링 설정이 각 서버가 아닌 프로메테우스 YAML에서 관리되기 때문에 모니터링 대상이나 메트릭 수집 주기 등과 같은 옵션을 유연하게 변경할 수 있다.
단점
일반적인 클러스터링 개념과 거리가 있다. 일반적으로 클러스터링이란 Replicas 간에 Discovery를 수행한 뒤, 데이터 샤딩과 장애 시 HA 등 무중단을 보장하는 개념이다.
하지만 프로메테우스는 각 Region마다 프로메테우스를 배치한 뒤 이를 Master에서 Aggregate 하는 구조이다.
대략적인 메트릭 추세 파악에는 좋지만, APM과 같이 발생한 모든 로그를 추적하고 문제가 발생했을 때는 적합하지 않다.
Reference